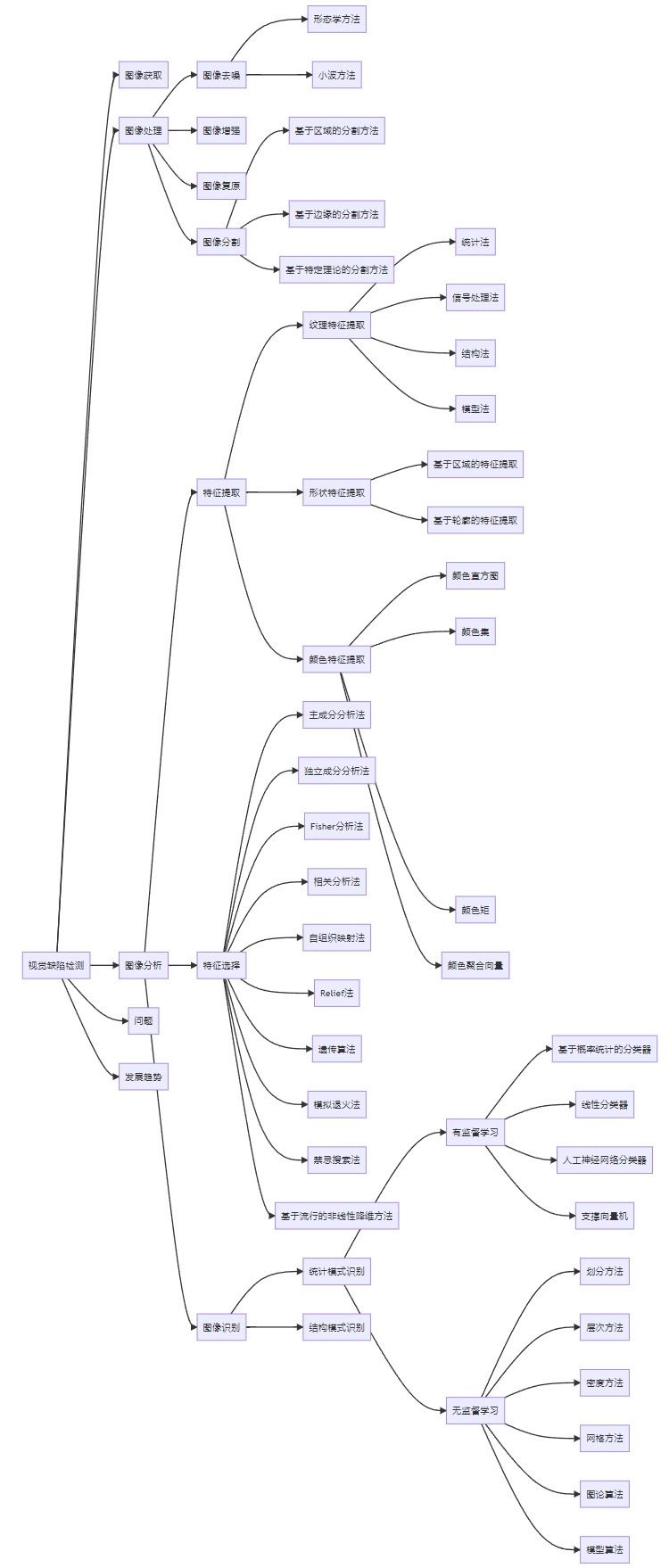
目标检测算法学习
主要任务
分类、定位、检测、分割、
主要方法
传统、基于深度学习
基础知识
选择搜索
非极大抑制
标注工具
- labelimg
- lableme
基于深度学习方法
Anchor-Based、Anchor-Free方法,其区别是是否使用Anchor进行训练和预测.
Anchor-based方法则包括Two stage和One stage算法,Anchor-Free算法近几年逐步完善。
- 候选区域产生(滑窗法、选择搜索法)
- 交互比(IoU)评估效果
- 非极大抑制(NMS)
疑问:
NMS操作时需要和真实框作IoU,是否只在训练时使用,测试时仅作指标评估?Anchor-based:Two stage
主要思想和区别:进行区域生成(region proposal-RP)
特征提取→生成RP→分类/定位回归
常见方法:R-CNN系列
R-CNN
Rich feature hierarchies for accurate object detection and semantic segmentation (CVPR2014)
[paper] [code]
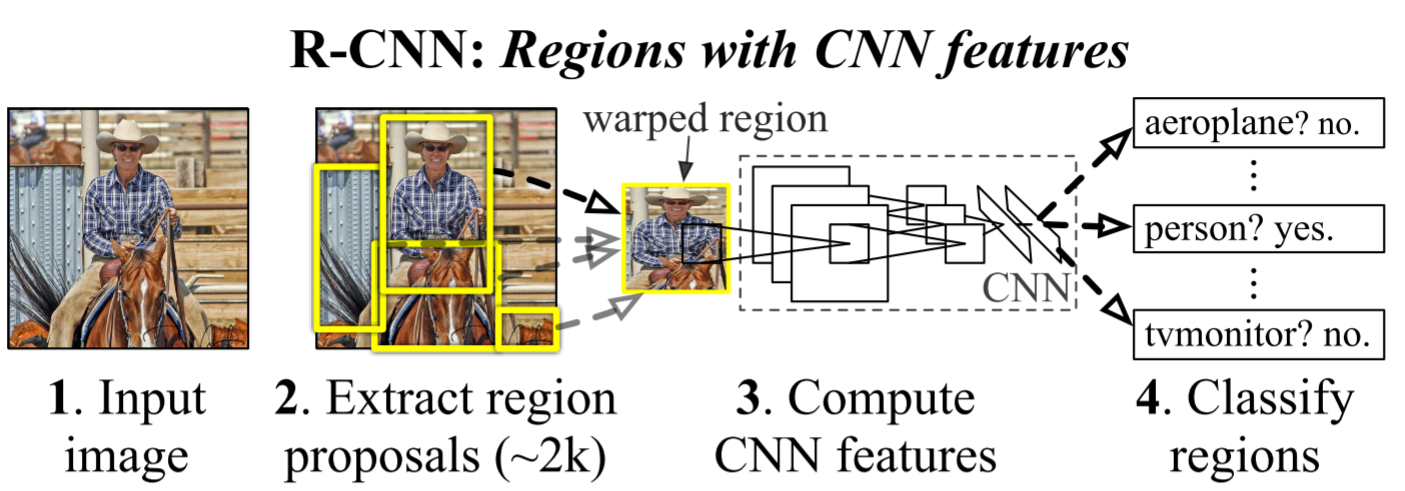
3个模块:
- RP(SS-选择性搜索,2000个RP)
- CNN(AlexNet)
- SVM(线性分类)
缺点:
- 速度慢
- 计算冗余,过程繁琐
- 空间消耗大
SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition (TPAMI)
[paper] [code]
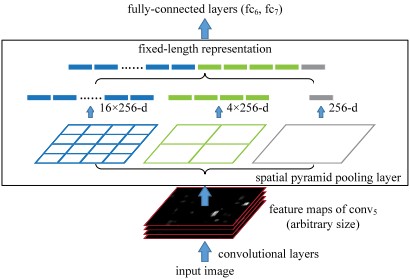
核心思想:
在最后一层卷积层和全连接层之间引入空间金字塔池化层是SPPNet,主要目的是对于任意尺寸的输入产生固定大小的输出。
[参考]
思路是对于任意大小的feature map首先分成16、4、1个块,然后在每个块上最大池化,池化后的特征拼接得到一个固定维度的输出,以满足全连接层的需要。
当使用SPPNet网络用于目标检测时,整个图像只需计算一次即可生成相应特征图,不管候选框尺寸如何,经过SPP之后,都能生成固定尺寸的特征表示图,这避免了卷积特征图的重复计算。
先提取特征再进行区域选择!
Fast R-CNN
Fast R-CNN (ICCV 2015)
[paper] [code]
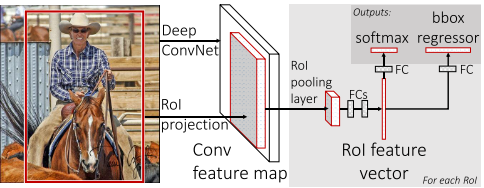
与R-CNN和SPP-Net相同:
- 同样使用SS获取RP
- 直接原图进行特征提取实现特征图共享,在特征图中找到每一个RP对应的区域并截取特征图中的RP,用一个单层的SSP layer来统一到一样的尺度(ROI pooling)
改进优势:
- ⽹络末尾采⽤并⾏的不同的全连接层,可同时输出分类结果和窗⼝回归结果, 实现了end-to-end的多任务训练。
- 直接将CNN、分类器、边界框回归器整合到一个网络,将原来三个模型整合到一个网络,便于训练,极大地提高了训练的速度。
- 不需要存储中间特征向量用于SVM分类和回归模型训练
- 训练可以更新所有层的参数
- 所有的训练任务是单阶段完成的,使用multi-task loss(分类损失+框回归损失)
Faster R-CNN
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (NIPS2015)
[paper] [code]
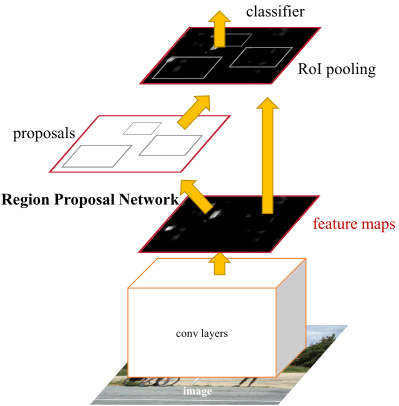
改进优势:
- 使用RPN网络代替选择性搜索(SS)进行候选区域的提取
- RPN的输入是最初经过卷积生成的特征图,与后续RoI pooling共享,节省时间;输出为一组矩形目标推荐框含有目标的一个概率值和四个坐标值
- RPN网络将候选区域的提取任务建模为二分类(是否为物体)的问题,通过softmax判断anchors属于positive还是negative,再利用边界框回归修正anchors获得精确的推荐框proposals
- RoI pooling以特征图和推荐框同时为输入提取得到推荐特征图(proposal feature maps),再传入全连接层预测类别并进行边界框回归获取检测框的最终位置
- 损失函数:二分类损失+坐标回归损失
$p_i$和$t_i$是每个框的预测概率和预测边界坐标向量,$p_i^$和$t_i^$是真实框对应的概率和坐标。
对于Anchor是否为正:Anchors与GT的IOU值最高的Anchor为正;与GT的IOU大于0.7的Anchors为正
FPN
Feature Pyramid Networks for Object Detection(CVPR2017)
[paper] [code]
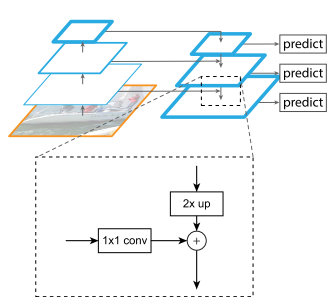
Bottom-up:输入图片经过骨干网络提取特征,尺寸减小,得到高层次语义、低分辨率特征图;
Top-down:高层特征图上采样(最近邻采样,扩大2倍),使得低层高分辨率特征也包含丰富语义信息;
Lateral connection:每个stage输出的特征图$Cn$先进行一个$1 \times 1$的卷积降维(降低通道数),再与上一层输出$P{n+1}$上采样得到的特征图直接相加得到$P_n$。
注:每一个阶段最终的特征图是由相加后的特征图再次经过一个$3 \times 3$的卷积核得到的,主要是减轻最近邻近插值带来的混叠影响(周围的数都相同)。
FPN用于RPN:每一层特征具有不同的尺度信息,都单独经过一个网络头,处理1:1,1:2,2:1三种长宽比的候选框,所有网络头参数共享。
FPN用于Fast R-CNN:进行RoI pooling时,不同尺度的RoI应该使用不同特征层作为输入,用那一层用下式决定:$k=\lfloor k_{0} + log_2(\sqrt{wh}/224) \rfloor$
$k_0=5$ (基准值),$w$和$h$是RoI的宽和高。
问题:最终的15个anchor怎么用?
Mask R-CNN
Mask R-CNN(ICCV2017)
[paper] [code]
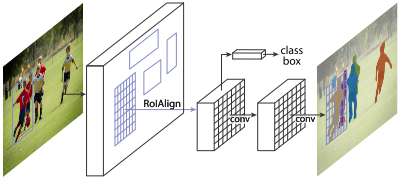
就是在原始Faster-rcnn算法的基础上面增加FCN来产生对应的MASK分支。
即Faster-rcnn + FCN,更细致的是 RPN + ROIAlign + Fast-rcnn + FCN
Anchor-based:One stage
SSD
SSD: Single Shot MultiBox Detector(ECCV2016)
[paper] [code]
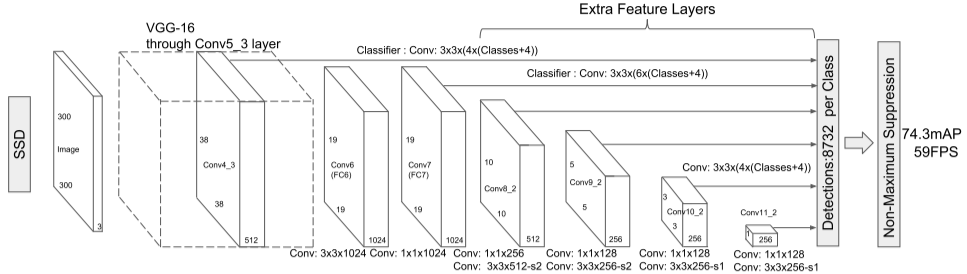
主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度快,但均匀的密集采样会导致正样本与负样本(背景)极其不均衡,从而训练比较困难,导致模型准确度稍低。
SSD的主干网络是VGG,按上图进行卷积操作,从$300 \times 300 \times 3$最终变成$1 \times 1 \times 256$。
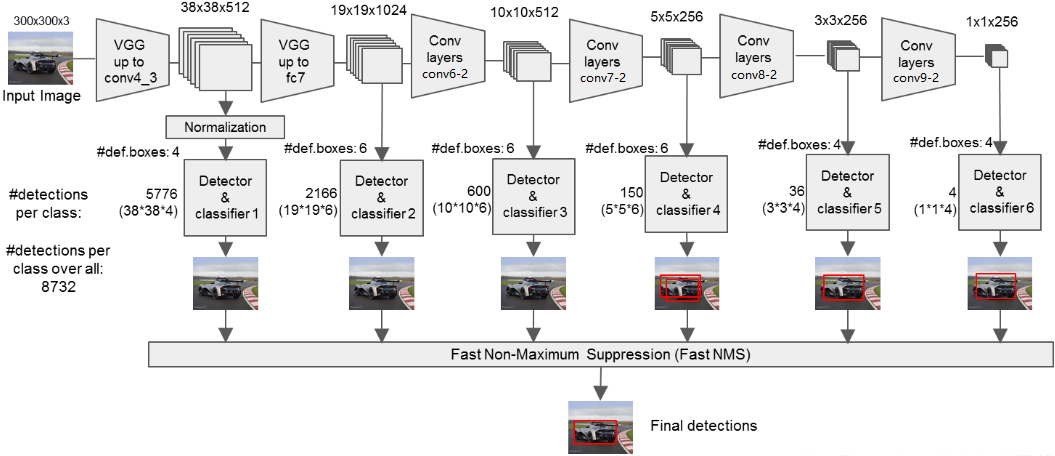
SSD和YOLOV1的不同在于SSD采用金字塔结构,利用了多个大小不同的特征层(conv4-3,fc7,conv6-2,conv7-2,conv8_2,conv9_2)同时进行分类和位置回归,称为有效特征层。
对获取到的每一个有效特征层,我们都需要对其做两个卷积操作,一次$num_anchors \times 4$的卷积(用于预测该特征层上每一个网格点上每一个先验框的变化情况,对每一个有效特征层对应的先验框进行调整获得预测框)和一次$num_anchors \times num_classes$的卷积(用于预测该特征层上每一个网格点上每一个预测对应的种类),而num_anchors指的是该特征层每一个特征点所拥有的先验框数量,即num_priors。上述提到的六个特征层,每个特征层的每个特征点对应的先验框数量分别为4、6、6、6、4、4。
具体来说,图像被分成与有效特征层长宽对应的网格,每个网格从中心建立num_anchor个先验框,$num_anchors \times 4$卷积的4表示x_offset、y_offset、h和w,从而调整所有先验框的位置和大小,最后通过NMS筛选。
在训练过程中,每一个真实框可以由多个先验框负责预测(计算iou,大于一定门限),但每一个先验框只能负责与其iou最大的真实框的预测。
计算loss时,loss函数是相对于SSD网络的预测结果的,所以需要先对真实框进行编码,转将基于原图大小的真实框映射到SSD的输出空间上,然后计算loss,loss包括位置损失(L1 loss)+分类/置信度损失(交叉熵 loss).
注意:前面提到正样本与负样本极其不均衡,所以计算loss时选择highest confidence loss(先计算所有loss,再排序)作为负样本,正负样本的比例为1:3。
YOLO
yolov1
You Only Look Once: Unified, Real-Time Object Detection(CVPR2016)
[paper] [code]
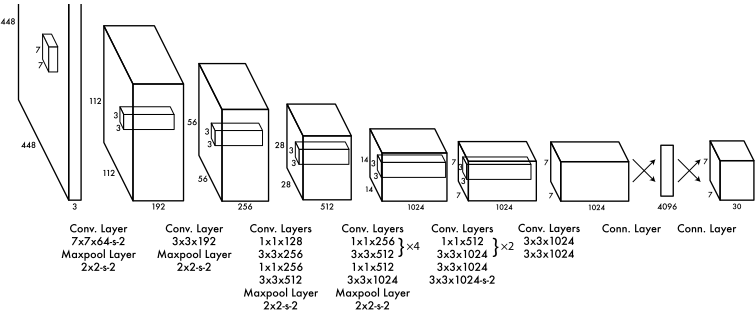
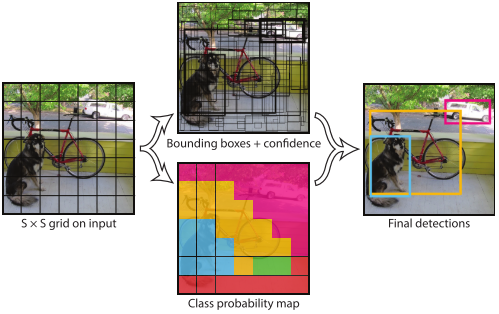
网络输入为彩色图像,输入图像被划分为$S \times S$的网格,每一个网格预测$B$个bounding box$(x,y,w,h,confidence)$,每个网格还要预测一个类别信息($C$类),所以网络输出是一个$S \times S \times (5 \times B + C)$的张量
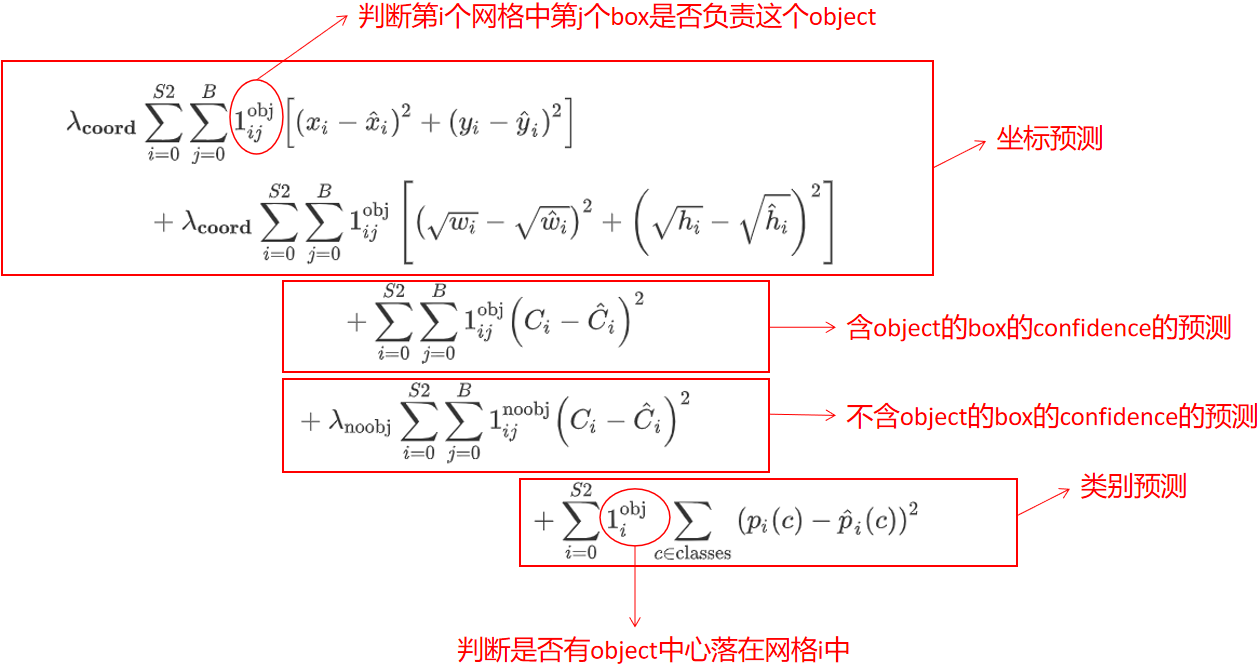
在推理过程中并不是把每个单独的网格作为输入,网格只是用于物体GT中心点位置的分配,如果一个物体的GT中心点坐标在一个网格中,那么就认为这个网格就是包含这个物体,这个物体的预测就由该网格负责。而不是对图片进行切片,并不会让网格的视野受限且只有局部特征。
推理过程中,每个网格都将预测2个bbox以及属于20个类别的概率,再用NMS去除冗余框
loss由三部分组成:坐标预测损失、置信度预测损失、类别预测损失
优点:
- 检测速度快
- 迁移能力强
缺点
- 对靠得太近的物体,密集的小物体检测效果差
- 对不常见的角度的目标泛化性能偏弱
- 容易产生定位错误
yolov2
YOLO9000: Better, Faster, Stronger(CVPR2017)
[paper] [code]
yolov3
YOLOv3: An Incremental Improvement
[paper] [code]
yolov4
YOLOv4: Optimal Speed and Accuracy of Object Detection
[paper] [code]
yolov5
yolov6
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
[paper] [code]
yolov7
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
[paper] [code]
yolov8
Retinanet
Anchor-Free
 微信
微信 支付宝
支付宝